This is the fourth in a series about archiving to removable media (optical discs such as BD-Rs and DVD+Rs or portable hard drives). Here are the first three parts:
- In part 1, I laid out my goals for the project, and considered a number of tools before determining dar and git-annex were my leading options.
- In part 2, I took a deep dive into git-annex and simulated using it for this project.
- In part 3, I did the same with dar.
- And in this part, I want to put it together to come up with an initial direction to pursue.
I want to state at the outset that this is not a general review of dar or git-annex. This is an analysis of how those tools stack up to a particular use case. Neither tool focuses on this use case, and I note it is particularly far from the more common uses of git-annex. For instance, both tools offer support for cloud storage providers and special support for ssh targets, but neither of those are in-scope for this post.
Comparison Matrix
As part of this project, I made a
comparison matrix which includes not just dar and git-annex, but also backuppc, bacula/bareos, and borg. This may give you some good context, and also some reference for other projects in this general space.
Reviewing the Goals
I identified some goals in part 1. They are all valid. As I have thought through the project more, I feel like I should condense them into a simpler ordered list, with the first being the most important. I omit some things here that both dar and git-annex can do (updates/incrementals, for instance; see the expanded goals list in part 1). Here they are:
- The tool must not modify the source data in any way.
- It must be simple to create or update an archive. Processes that require a lot of manual work, are flaky, or are difficult to do correctly, are unlikely to be done correctly and often. If it s easy to do right, I m more likely to do it. Put another way: an archive never created can never be restored.
- The chances of a successful restore by someone that is not me, that doesn t know Linux, and is at least 10 years in the future, should be maximized. This implies a simple toolset, solid support for dealing with media errors or missing media, etc.
- Both a partial point-in-time restore and a full restore should be possible. The full restore must, at minimum, provide a consistent directory tree; that is, deletions, additions, and moves over time must be accurately reflected. Preserving modification times is a near-requirement, and preserving hard links, symbolic links, and other POSIX metadata is a significant nice-to-have.
- There must be a strategy to provide redundancy; for instance, a way for one set of archive discs to be offsite, another onsite, and the two to be periodically swapped.
- Use storage space efficiently.
Let s take a look at how the two stack up against these goals.
Goal 1: Not modifying source data
With dar, this is accomplished.
dar --create does not modify source data (and even has a mode to avoid updating atime) so that s done.
git-annex normally does modify source data, in that it typically replaces files with symlinks into its hash-indexed storage directory. It can instead use hardlinks. In either case, you will wind up with files that have identical content (but may have originally been separate, non-linked files) linked together with git-annex. This would cause me trouble, as well as run the risk of modifying timestamps. So instead of just storing my data under a git-annex repo as is its most common case, I use the directory special remote with importtree=yes to sort of import the data in. This, plus my desire to have the repos sensible and usable on non-POSIX operating systems, accounts for a chunk of the git-annex complexity you see here. You wouldn t normally see as much complexity with git-annex (though, as you will see, even without the directory special remote, dar still has less complexity).
Winner: dar, though I demonstrated a working approach with git-annex as well.
Goal 2: Simplicity of creating or updating an archive
Let us simply start by recognizing this:
- Number of commands to create a first dar archive, including all splits: 1
- Number of commands to create a first git-annex archive, with just the first two splits: 58
- Number of commands to create a dar incremental: 1
- Number of commands to update the last git-annex drive: 10
- Number of commands to do a full restore of all slices and both archives with dar: 2 (1 if dar_manager used)
- Number of commands to do a full restore of just the first two drive with git-annex: 9 (but my process may not be correct)
Both tools have a lot of power, but I must say, it is easier to wrap my head around what dar is doing than what git-annex is doing. Everything dar does is with files: here are the files to archive, here is an archive file, here is a detached (isolated) catalog. It is very straightforward. It took me far less time to develop my dar page than my git-annex page, despite having existing familiarity with both tools. As I pointed out in part 2, I still don t fully understand how git-annex syncs metadata. Unsolved mysteries from that post include why the two git-annex drives had no idea what was on the other drives, and why the export operation silenty did nothing. Additionally, for the optical disc case, I had to create a restricted-size filesystem/dataset for git-annex to write into in order to get the desired size limit.
Looking at the optical disc case, dar has a lot of nice infrastructure built in. With pause and execute, it can very easily be combined with disc burning operations. slice will automatically limit the size of a given slice, regardless of how much disk space is free, meaning that the git-annex tricks of creating smaller filesystems/datasets are unnecessary with dar.
To create an initial full backup with dar, you just give it the size of the device, and it will automatically split up the archive, with hooks to integrate for burning or changing drives. About as easy as you could get.
With git-annex, you would run the commands to have it fill up the initial filesystem, then burn the disc (or remove the drive), then run the commands to create another repo on the second filesystem, and so forth.
With hard drives, with git-annex you would do something similar; let it fill up a repo on a drive, and if it exits with a space error, swap in the next. With dar, you would slice as with an optical disk. Dar s slicing is less convenient in this case, though, as it assumes every drive is the same size and yours may not be. You could work around that by using a slice size no bigger than the smallest drive, and putting multiple slices on larger drives if need be. If a single drive is large enough to hold your entire data set, though, you need not worry about this with either tool.
Here s a warning about git-annex: it
won t store anything beneath directories named .git. My use case doesn t have many of those. If your use case does, you re going to have to figure out what to do about it. Maybe rename them to something else while the backup runs? In any case, it is simply a fact that git-annex cannot back up git repositories, and this cuts against being able to back up things correctly.
Another point is that git-annex has scalability concerns. If your archive set gets into the hundreds of thousands of files, you may need to split it into multiple distinct git-annex repositories. If this occurs and it will in my case it may serve to dull the shine of some of git-annex s features such as location tracking.
A detour down the update strategies path
Update strategies get a little more complicated with both. First, let s consider: what exactly should our update strategy be?
For optical discs, I might consider doing a monthly update. I could burn a disc (or more than one, if needed) regardless of how much data is going to go onto it, because I want no more than a month s data lost in any case. An alternative might be to spool up data until I have a disc s worth, and then write that, but that could possibly mean months between actually burning a disc. Probably not good.
For removable drives, we re unlikely to use a new drive each month. So there it makes sense to continue writing to the drive until it s full. Now we have a choice: do we write and preserve each month s updates, or do we eliminate intermediate changes and just keep the most recent data?
With both tools, the monthly burn of an optical disc turns out to be very similar to the initial full backup to optical disc. The considerations for spanning multiple discs are the same. With both tools, we would presumably want to keep some metadata on the host so that we don t have to refer to a previous disc to know what was burned. In the dar case, that would be an isolated catalog. For git-annex, it would be a metadata-only repo. I illustrated both of these in parts 2 and 3.
Now, for hard drives. Assuming we want to continue preserving each month s updates, with dar, we could just write an incremental to the drive each month. Assuming that the size of the incremental is likely far smaller than the size of the drive, you could easily enough do this. More fancily, you could look at the free space on the drive and tell dar to use that as the size of the first slice. For git-annex, you simply avoid calling drop/dropunused. This will cause the old versions of files to accumulate in .git/annex. You can get at them with git annex commands. This may imply some degree of elevated risk, as you are modifying metadata in the repo each month, which with dar you could chmod a-w or even chattr +i the archive files once written. Hopefully this elevated risk is low.
If you don t want to preserve each month s updates, with dar, you could just write an incremental each month that is based on the previous drive s last backup, overwriting the previous. That implies some risk of drive failure during the time the overwrite is happening. Alternatively, you could write an incremental and then use dar to merge it into the previous incremental, creating a new one. This implies some degree of extra space needed (maybe on a different filesystem) while doing this. With git-annex, you would use drop/dropunused as I demonstrated in part 2.
The winner for goal 2 is dar. The gap is biggest with optical discs and more narrow with hard drives, thanks to git-annex s different options for updates. Still, I would be more confident I got it right with dar.
Goal 3: Greatest chance of successful restore in the distant future
If you use git-annex like I suggested in part 2, you will have a set of discs or drives that contain a folder structure with plain files in them. These files can be opened without any additional tools at all. For sheer ability to get at raw data, git-annex has the edge.
When you talk about getting a consistent full restore without multiple copies of renamed files or deleted files coming back then you are going to need to use git-annex to do that.
Both git-annex and dar provide binaries. Dar provides a win64 version on
its Sourceforge page. On the author s
releases site, you can find the win64 version in addition to a statically-linked x86_64 version for Linux. The git-annex
install page mostly directs you to package managers for your distribution, but the
downloads page also lists builds for Linux, Windows, and Mac OS X. The Linux version is dynamic, but ships most of its .so files alongside. The Windows version requires cygwin.dll, and all versions require you to also install git itself. Both tools are in package managers for Mac OS X, Debian, FreeBSD, and so forth. Let s just say that you are likely to be able to run either one on a future Windows or Linux system.
There are also GUI frontends for dar, such as
DARGUI and
gdar. This can increase the chances of a future person being able to use the software easily. git-annex has the assistant, which is based on a different use case and probably not directly helpful here.
When it comes to doing the actual restore process using software, dar provides the easier process here.
For dealing with media errors and the like, dar can integrate with par2. While technically you could use par2 against the files git-annex writes, that s more cumbersome to manage to the point that it is likely not to be done. Both tools can deal reasonably with missing media entirely.
I m going to give the edge on this one to git-annex; while dar does provide the easier restore and superior tools for recovering from media errors, the ability to access raw data as plain files without any tools at all is quite compelling. I believe it is the most critical advantage git-annex has, and it s a big one.
Goal 4: Support high-fidelity partial and full restores
Both tools make it possible to do a full restore reflecting deletions, additions, and so forth. Dar, as noted, is easier for this, but it is possible with git-annex. So, both can achieve a consistent restore.
Part of this goal deals with fidelity of the restore: preserving timestamps, hard and symbolic links, ownership, permissions, etc. Of these, timestamps are the most important for me.
git-annex can t do any of that. dar does all of it.
Some of this can be worked around using mtree as I documented in part 2. However, that implies a need to also provide mtree on the discs for future users, and I m not sure mtree really exists for Windows. It also cuts against the argument that git-annex discs can be used without any tools. It is true, they can, but all you will get is filename and content; no accurate date. Timestamps are often highly relevant for everything from photos to finding an elusive document or record.
Winner: dar.
Goal 5: Supporting backup strategies with redundancy
My main goal here is to have two separate backup sets: one that is offsite, and one that is onsite. Depending on the strategy and media, they might just always stay that way, or periodically rotate. For instance, with optical discs, you might just burn two copies of every disc and store one at each place. For hard drives, since you will be updating the content of them, you might swap them periodically.
This is possible with both tools. With both tools, if using the optical disc scheme I laid out, you can just burn two identical copies of each disc.
With the hard drive case, with dar, you can keep two directories of isolated catalogs, one for each drive set. A little identifier file on each drive will let you know which set to use.
git-annex can track locations itself. As I demonstrated in part 2, you can make each drive its own repo, add all drives from a given drive set to a git-annex group. When initializing a drive, you tell git-annex what group it s a prt of. From then on, git-annex knows what content is in each group and will add whatever a given drive s group needs to that drive.
It s possible to do this with both, but the winner here is git-annex.
Goal 6: Efficient use of storage
Here are situations in which one or the other will be more efficient:
- Lots of small files: dar, due to reduced filesystem overhead
- Compressible data: dar (git-annex doesn t support compression)
- Renamed files: git-annex (it will detect the sha256 match and avoid storing a duplicate copy)
- Identical files: git-annex, unless they are hardlinked already (again, detects the sha256 match)
- Small modifications to files (eg, ID3 tags on MP3s, EXIF data on photos, etc): dar (it supports rsync-style binary deltas)
The winner depends on your particular situation.
Other notes
While not part of the goals above, dar is capable of using tapes directly. While not as common, they are often used in communities of people that archive lots of data.
Conclusions
Overall, dar is the winner for me. It is simpler in most areas, easier to get correct, and scales very well.
git-annex does, however, have some quite compelling points. Being able to access files as plain files is huge, and its location tracking is nicer than dar s, even when using dar_manager.
Both tools are excellent and I recommend them both and for more than the particular scenario shown here. Both have fantastic and responsive authors.
 Photo by Taylor Vick (Unsplash)
Photo by Taylor Vick (Unsplash)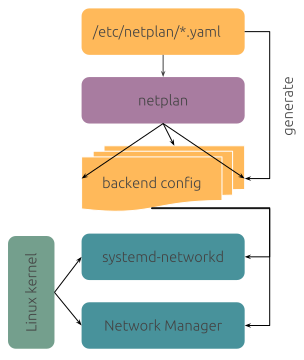 Design overview (netplan.io)
Design overview (netplan.io)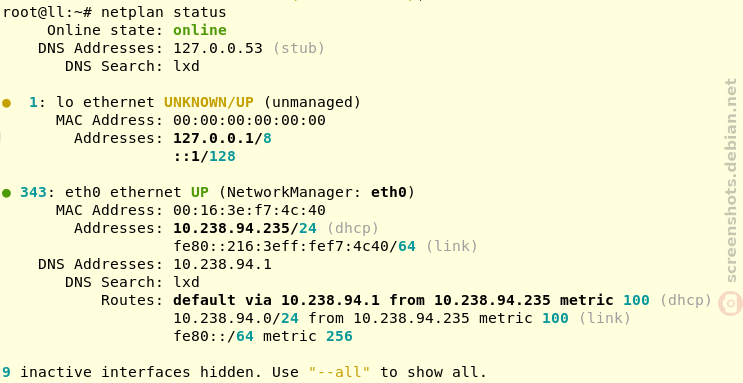 Netplan status (Debian)
Netplan status (Debian) I m six months into my journey of building a business which means its time to reflect and review the goals I set for the year.
I m six months into my journey of building a business which means its time to reflect and review the goals I set for the year.

 One of my earlier Slackware install disk sets, kept for nostalgic reasons.
One of my earlier Slackware install disk sets, kept for nostalgic reasons. The phrase "Root of Trust" turns up at various points in discussions about verified boot and measured boot, and to a first approximation nobody is able to give you a coherent explanation of what it means[1]. The Trusted Computing Group has a fairly wordy
The phrase "Root of Trust" turns up at various points in discussions about verified boot and measured boot, and to a first approximation nobody is able to give you a coherent explanation of what it means[1]. The Trusted Computing Group has a fairly wordy  Just a few days back we came to know about the horrific Train Crash that happened in Odisha (Orissa). There are some things that are known and somethings that can be inferred by observance. Sadly, it seems the incident is going to be covered up
Just a few days back we came to know about the horrific Train Crash that happened in Odisha (Orissa). There are some things that are known and somethings that can be inferred by observance. Sadly, it seems the incident is going to be covered up  . Some of the facts that have not been contested in the public domain are that there were three lines. One loop line on which the Goods Train was standing and there was an up and a down line. So three lines were there. Apparently, the signalling system and the inter-locking system had issues as highlighted by an official about a month
. Some of the facts that have not been contested in the public domain are that there were three lines. One loop line on which the Goods Train was standing and there was an up and a down line. So three lines were there. Apparently, the signalling system and the inter-locking system had issues as highlighted by an official about a month 





 On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the
On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the  On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in
On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in  In
In 
 Just some of the organisations that leaked data in 2022
Just some of the organisations that leaked data in 2022
 Not very useful for a database
Not very useful for a database
 Indeed
Indeed
 Everyone who uses a database...
Everyone who uses a database...